In Kürze: Das Studiendesign mit zum Teil 40.000 Probanden vermittelt ein falsches Sicherheitsgefühl bei den Menschen. Es können – auch bei einer scheinbar sehr großen Anzahl an Probanden – in einem Zeitraum wie einem halben Jahr oder auch Jahr, keine validen Daten zur Wirksamkeit der Impfstoffe vorliegen.
Das Problem ist nämlich, dass wir Menschen aus ethischen Gründen nicht „von Hand“ bewusst anstecken dürfen.
Die Frage ist: woher weiß ich, wann die Probanden eine entsprechende Viruslast abbekommen haben?
Die Antwort: genau das weiß man nicht.
Fakt ist: genau hier ist sprichwörtlich „der Hund begraben“ – sogar das RKI gibt keinen Anhalt für die Wahrscheinlichkeit an, sich in Deutschland im Monat x als „Durchschnittsbürger“ anzustecken.
Auf unserer Website hier oder auf unserem Telegram Kanal hat man die Möglichkeit mit Kommentaren uns Rückmeldung zu geben bzw. mit uns auch in den Diskurs zu treten. Zu unserem Beitrag über eine simple Auswertung der Statistiken der britischen Gesundheitsbehörde erhielten wir zahlreiche solcher Kommentare – die uns zeigten, dass vielen Personen noch nicht die grundlegenden Mängel der aktuellen Studien bekannt sind. Da fanden wir Sätze wie:
Die Frage Wenn Sie ein Zufallsexperiment mehrmals ausführen und die Ausgänge notieren, dann erhalten Sie relative Häufigkeit eines Ereignisses. Zum Beispiel: Wie häufig werden Menschen mit und ohne Impfung krank.
Dabei kennen Sie die tatsächliche Wahrscheinlichkeit eines Ereignisses gar nicht, Sie versuchen aber durch die wiederholte Ausführung in die Nähe der tatsächlichen Wahrscheinlichkeit zu kommen.
Wenn Sie also in der Studie viele Menschen haben, wo geschaut wurde, welcher Anteil mit Impfung noch erkrankt und welcher ohne Impfung, dann sind diese relativen Häufigkeiten sehr sicher sehr nah an der tatsächlichen Wahrscheinlichkeit.
Genau dieser Aspekt – der oberflächlich betrachtet zu stimmen scheint – ist leider in dem speziellen Fall der Impfstudien nicht richtig. Zeit für das Corona Blog Team, Licht ins Dunkel zu bringen. Wir wollen in diesem Beitrag zwei elementare Mängel an der Darstellung der Studien und ihrer Systematik aufwerfen:
- Die Angabe der relativen Wirksamkeit verzerrt absichtlich die vorläufigen Resultate der Studie – und zwar extrem
- Das Studiendesign ist – bedingt durch einfache statistische Überlegungen – so ausgelegt, dass es über eine lange Zeit laufen muss, um valide Daten zu liefern
Fangen wir also an, auf diese beiden Punkte einzugehen.
1. Relative Wirksamkeit – oder extrem subjektive Zahlendarstellung
Wir haben es schon mehrfach erläutert und geschrieben: die relative Wirksamkeit ist ein Marketingtrick der Pharmaindustrie und stellt die Ergebnisse verfälscht dar. Das Thema ist allerdings so wichtig, dass wir es hier noch einmal erläutern wollen – und zwar am Beispiel der BioNTech-Pfizer Studie zur Wirksamkeit des mRNA Vakzins gegen die Südafrika Variante – wir erinnern uns, die wird mit „100% Wirksamkeit“ angegeben.
Um diese zu ermitteln wurde eine Studie durchgeführt, über die nur grobe Details bekannt sind: Es gab 800 Probanden in zwei Gruppen, am Ende hatten sich nach „bis zu einem halben Jahr nach der zweiten Dosis“ ganze 6 Personen in der ungeimpften Gruppe infiziert. Exaktere Angaben konnten wir nicht finden – dennoch reicht dies für eine Darstellung des Problems aus.
Stellen wir das Szenario in einem Bild dar:
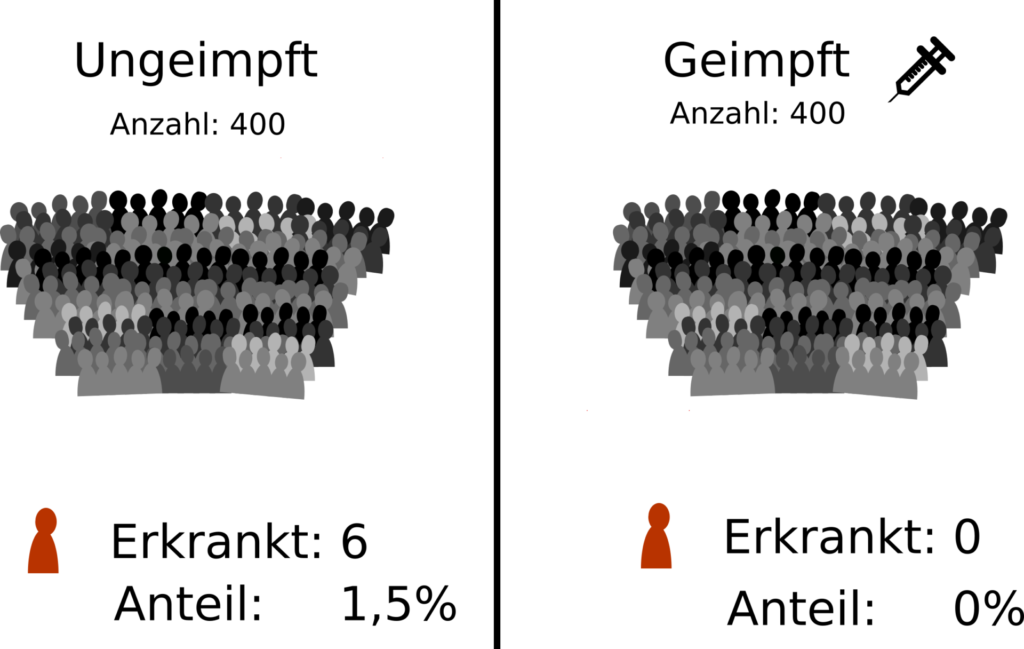
Wir haben also 2 Gruppen zu (im Idealfall) je 400 Personen – die ebenfalls im Idealfall zufällig ausgewählt sind. Diese wurden (schon wieder im Idealfall) 6 Monate nach dem Piks (mit Impfstoff oder Placebo) beobachtet. 6 Personen in der Placebo Gruppe erkrankten – und zwar mindestens so schwer, dass sie Symptome hatten. Diese 6 Personen entsprechen 1,5% der ungeimpften Gruppe. In der geimpften Gruppe erkrankte keiner – d.h. 0%.
Daraus kann man schlussfolgern, dass das Risiko mit der Impfung zu erkranken in dieser Studie um absolut gesehen 1,5% geringer ist. Man spricht dann auch von Prozentpunkten.
Sprich: Die Impfung reduziert das Risiko einer Erkrankung in dieser 6 Monatsstudie um 1,5 Prozentpunkte.
Wie kommt nun BioNTech-Pfizer auf 100% Wirksamkeit? Ganz einfach, sie nutzen die – meist zu Marketingzwecken herangezogene – relative Wirksamkeit. Diese berechnet sich durch die Differenz der Wirksamkeiten und bezieht dann nochmal das Ergebnis auf die Wirksamkeit der ungeimpften Gruppe:

Durch diesen irreführenden Bezug (nochmal auf die absolute Wirksamkeit in der ungeimpften Gruppe) entsteht der falsche Eindruck, dass wirklich alle Menschen durch die Impfung vor der Erkrankung geschützt sind. Dies ist eine extrem verfälschte, hoch subjektive Art der Zahlendarstellung – extrem zu Gunsten der Pharmaindustrie.
Die absolute Wirksamkeit (1,5 Prozentpunkte geringeres Risiko) hat entscheidende Vorteile. Sie zeigt…
- direkt, dass die beiden Gruppen sich in ihren Ansteckungsraten ähneln (sonst wäre der Abstand in Prozentpunkten größer)
- dass der Vorteil der „geimpften Gruppe“ in dieser kurzen Studie lediglich 1,5 Prozentpunkte ist
Diese Darstellung ist also objektiver und stellt das Ganze nüchterner dar – eben an dem realen Sachverhalt orientiert. Dennoch findet man diese Zahl in den Studien von BioNTech-Pfizer nicht. Das überrascht eigentlich nicht wirklich – was dennoch überrascht ist, dass sogar die Öffentlich Rechtlichen diese offensichtlichen Werbezahlen der Pharmaindustrie unkritisch und ungefiltert weitergeben.
Dies zur Kritik an der reinen Form der Studien. Kommen wir nun zum „Eingemachten“ und zum zweiten Punkt: Kritik an den Aussagen zur Wirksamkeit aufgrund des Studiendesigns.
2. Das Studiendesign ist auf lange Dauer ausgelegt
Harte Theorie: Das Gesetz der großen Zahlen
Hier müssen wir einen kleinen Ausschweif über die Statistik machen – allerdings nur über die absoluten Grundlagen. Da gibt es das wichtige „Gesetz der großen Zahlen“, das im Grunde besagt, dass:
Die relative Häufigkeit eines Zufallsexperiments häuft sich bei häufiger Wiederholung um die theoretische Wahrscheinlichkeit eines Zufallsergebnisses an.
Klingt kompliziert – ist es aber nicht. Machen wir uns das Ganze an einem einfachen Beispiel klar: Nehmen wir an, wir wollen ins Casino gehen und dort fleißig um Geld würfeln – und zwar mit einem vierseitigen Würfel. Ja, so etwas gibt es:

Bei einem ungezinkten Würfel wie dem auf dem Bild, da wissen wir: jede Seite hat die gleiche Wahrscheinlichkeit zu erscheinen, nämlich bei dem 4-seitigen Würfel genau 25% (das wird im Gesetz „theoretische Wahrscheinlichkeit“ genannt).
Dies können wir überprüfen, wenn wir viele, viele Würfelversuche machen und uns notieren, welche Seite oben liegt. Bei vielen Versuchen sollte jede Seite genau 25% aller Würfelversuche oben liegen. Dies garantiert uns das Gesetz der großen Zahlen – bei einem ungezinkten Würfel.
Natürlich kann es sein, dass bei den ersten Versuchen „zufällig“ immer dieselbe Seite oben liegt – und wir einfach „Pech haben“. Aber: Das Gesetz der großen Zahlen garantiert uns, dass wenn wir viele, viele Würfelversuche machen, jede Seite zu 25% oben liegen wird.
Gehen wir langsam zu einem Experiment über
Nehmen wir an, wir wollen 2 unterschiedliche Casinos überprüfen und schauen, ob deren 4-seitige Würfel gezinkt sind.
Wie machen wir das? Wir gehen in Casino A, nehmen deren Würfel und machen unzählige Würfelversuche. Im Idealfall sollte jede Seite 25% aller Würfelversuche oben liegen. Wir machen danach dasselbe bei Casino B, wo wir dasselbe erwarten. Weicht unser Ergebnis nach unzähligen Versuchen davon ab, dann will ein Casino betrügen. Beispielsweise wenn in Casino A zu 40% eine Seite oben liegt, wissen wir, dass mit dem Würfel etwas nicht stimmt.
Warum?
Laut dem Gesetz der großen Zahlen sollten alle Seiten gegen die theoretische Wahrscheinlichkeit von 25% oben liegen – wenn der Würfel perfekt ist.
Was haben wir in den beiden Casinos gemacht? Ein Experiment. Dies besteht aus zwei Dingen:
- Einem Ereignis: Wir würfeln
- Einem Ergebnis: Die Seite die oben liegt
Durch ständiges Wiederholen des Ereignisses (wir würfeln oft), bestätigen wir im Ergebnis die Aussage des Gesetzes der großen Zahlen.
Ein erster Bogen zu den Impfstudien
Ähnlich wie beim Würfelexperiment läuft das Ganze auch in den Studien der Impfhersteller zur Wirksamkeit der Impfstoffe ab. Wir haben hier nur nicht 2 Casinos, in denen wir das Experiment durchführen, sondern 2 Personengruppen: geimpfte und ungeimpfte Personen.
Schaut man sich die Sache recht oberflächlich an, dann ist die Sache klar: Wir haben eine Studie mit 800 Teilnehmern (bei unserem Beispiel mit der Südafrika Variante) – das ist schon eine „große Zahl“. Manche Studien sind ja, mit über 40.000 Teilnehmern, noch größer angelegt.
Schauen wir nun nach, wer erkrankt und wer nicht, dann sollte das Ergebnis bei vielen Versuchen gegen die reale Wirksamkeit gehen, sprich: Die Studie aus dem ersten Abschnitt sollte passen. Wir haben also 1,5 Prozentpunkte Wirksamkeitsvorteil der geimpften Gruppe – oder eben populistisch ausgedrückt: 100% relative Wirksamkeit.
Aber: Haben wir das wirklich?
Der Haken liegt beim Ereignis – über ethische Probleme
Was auf den ersten Blick ganz logisch aussieht – ist es aber nur auf den ersten Blick.
Die entscheidende Frage ist nämlich: Was ist denn das Ereignis in unserem „Impfexperiment“? Ist das der Piks – also die Gabe von Impfstoff oder Placebo?
Nein. Das eigentlich Ereignis findet nämlich erst nach der Impfung oder nach der Placebo-Gabe statt. Erst wenn wir eine Gruppe durchgeimpft haben geht ja das „eigentliche Experiment“ los: wir wollen die Probanden natürlich dem Virus aussetzen – und zwar in einer ordentlichen Dosis – und schauen, ob sich die Geimpften anstecken oder ob die Impfung hilft.
Und hier liegt die Krux: Natürlich ist es ethisch und moralisch nicht vertretbar, die Probanden bewusst einer „hohen Viruslast“ auszusetzen bzw. zu infizieren. Auch wenn es natürlich für unser Experiment „optimal“ wäre.
Ein genauerer Blick auf Ereignis und Ergebnis – hier liegt der Hund begraben
Schauen wir uns nochmal grafisch an, wie unser optimales Experiment aussehen würde:
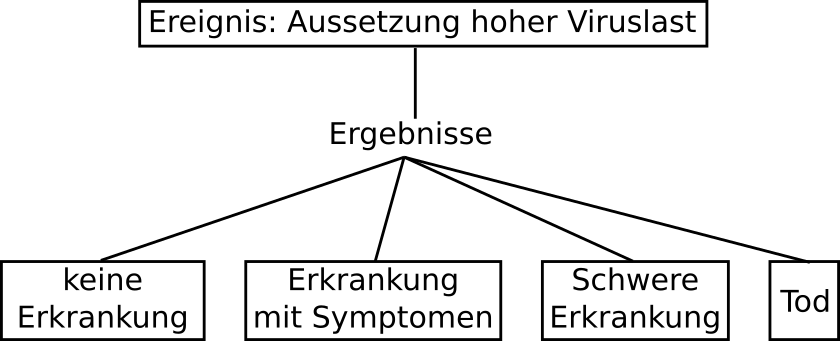
Wir haben also unser Ereignis (im Casino Beispiel der einfache Würfelwurf), also hier: das bewusste Aussetzen unserer Probanden mit einer hohen Viruslast – wo man weiß, sie würden sich normalerweise infizieren. Dazu haben wir vereinfacht hier vier mögliche Ergebnisse angenommen – in Anlehnung an den vierseitigen Würfel. Wenn wir das Ereignis in beiden Gruppen sehr, sehr oft „ausführen“ und die Wahrscheinlichkeiten deutlich voneinander abweichen – dann sehen wir (wahrscheinlich) einen Effekt der Impfung.
Das Problem ist immer noch das Ereignis: Da wir es aus ethischen Gründen nicht „von Hand“ auslösen dürfen, ist die Frage: woher weiß ich, wann die Probanden eine entsprechende Viruslast abbekommen haben? Sprich woher weiß man, dass das Experiment einmal ausgeführt wurde?
Die Antwort: genau das weiß man nicht.
Wir haben natürlich alle das alltägliche Risiko, diese Viruslast, die eine Erkrankung auslösen kann, abzubekommen. Aber das hängt von unzähligen Faktoren ab. Beispielsweise:
- Der Prävalenz, also wie groß ist der Anteil, der aktuell in der Bevölkerung infiziert ist? Ist die Prävalenz hoch, ist die Wahrscheinlichkeit höher, dass ich mich beim Treffen mit einer anderen Person anstecke.
- Dem persönlichen Verhalten: Wie oft treffe ich andere Personen? Bin ich ein verängstigter, älterer Mensch, der vom Dosenvorrat im Keller aus Angst vor den Bildern aus Bergamo lebt und gehe nicht mehr hinaus? Wie will ich dann jemals die für das Experiment nötige Viruslast abbekommen?
- Wo arbeite ich bzw. wie sind die Arbeitsbedingungen.
- Wie sind die politischen Rahmenbedingungen? Bei politisch erzwungener Ausgangssperre und geschlossenen Gaststätten ist das Risiko sich zu infizieren sicher auch geringer, als wenn man eine Nacht in der nächstgelegenen Kneipe mit zahlreichen Menschen verbringt.
Die Liste ließe sich endlos fortsetzen.
Fakt ist: genau hier ist sprichwörtlich „der Hund begraben“ – sogar das RKI gibt keinen Anhalt für die Wahrscheinlichkeit an, sich in Deutschland im Monat x als „Durchschnittsbürger“ anzustecken.
Eine grobe Abschätzung – als Anhalt
Für den Einzelhandel gibt es erste Ausarbeitungen um das Risiko hier pro Arbeitstag abschätzen zu können – aber auch dort ist ersichtlich, dass das Ergebnis von vielen Unbekannten abhängt.
Wir wollen – um ein Gefühl dafür zu bekommen – uns zumindest grob einen Anhalt verschaffen und nehmen dafür nur einen Schätzer für die Prävalenz, das heißt wie viele Personen in der Bevölkerung infiziert waren – bevor es den „Schutz“, die Impfung gab. Laut RKI Dashboard hatten im Zeitraum 01.03.2020 – 01.01.2021 (ca. Impfbeginn), d.h. über 306 Tage, ganze 1.765.063 Personen einen positiven PCR Test. Die Studie von BioNTech-Pfizer lief über ca. 6 Monate, d.h. 180 Tage. In dieser Zeit hatten in Deutschland geschätzt so viele Personen einen positiven PCR Test:

Bezogen auf die Einwohner (83,02 Millionen Menschen) hatten damit in dem halben Jahr 1,25% der Einwohner einen positiven PCR Test.
Schätzen wir die Anzahl der Experimente ab
Nehmen wir diesen groben Schätzer – 1,25% und beziehen ihn auf unsere eigentliches Experiment mit 800 Personen, bedeutet dies, dass lediglich

Experimente durchgeführt werden.
Was bedeutet dies jetzt? Nun – wie schon der Name unseres Gesetzes, das „Gesetz der großen Zahlen“, aussagt, dürfen wir nur aussagekräftige Ergebnisse erwarten, wenn wir eine große Anzahl an Experimenten durchführen, sprich wenn wir das Ereignis sehr, sehr oft durchführen.
Viele Menschen denken bei 800 oder 40.000 Probanden an eine Ereignisanzahl in dieser Größenordnung – das ist falsch, wie wir hier gezeigt haben. In der Realität wird nur ein marginaler Bruchteil davon wirklich an dem „Ereignis“ (viel Viruslast abbekommen) teilnehmen. Es ist anzunehmen, dass die 1,25% hier aus dem groben Überschlag noch deutlich zu hoch angesetzt ist (da bei den PCR Tests auch unzählige asymptomatische Personen und falsch-Positive erfasst wurden).
Wie kann man das Problem nun lösen?
Das Problem kann ganz einfach gelöst werden: Indem das Experiment lange – sehr lange, über mehrere Jahre – läuft. Warum? Es ist vermutlich einleuchtend, dass wenn das Experiment nur lange genug läuft, irgendwann der Großteil der Teilnehmer irgendwann einmal sein „Ereignis“ haben wird – sprich er wird eine hohe Dosis an Viruslast abbekommen.
Nicht umsonst laufen die Phase 3 Studien offiziell mit Masse bis 2023. Und nicht umsonst dauerten bislang Zulassungsverfahren von Impfstoffen eben Jahre.
Was jedoch auf jeden Fall in dem Artikel vermittelt werden sollen: Alleine durch das Studiendesign können – auch bei einer scheinbar sehr großen Anzahl an Probanden – in einem Zeitraum wie einem halben Jahr oder auch Jahr, keine validen Daten zur Wirksamkeit der Impfstoffe vorliegen.
Die bisherigen Rechnungen kann man nicht für valide Aussagen zur Wirksamkeit heranziehen – aufgrund einer deutlich zu kleinen Zahl an „Experimenten“. Dass die Pharmaindustrie und unsere Medien trotz diesem „Designfehler“ darüber hinaus noch die relative Wirksamkeit verkünden, spricht für sich.

Folgt uns gerne auch bei Telegram – Corona ist nicht das Problem dort veröffentlichen wir noch mehr Informationen.
34 Antworten auf „Entlarvt: Falsche Statistik bei den Wirksamkeitsstudien der Corona-Impfstoffe“
Impfwirksamkeit: Die Berechnung wie oben kann man so nicht machen. Mathematisch nicht, weil man in der Impfgruppe NULL annimmt.
Also wenn z.B. in der Impfgruppe auch 3 Personen erkrankt wären dann käme ein mathematisch sinnvoller Wert von 50% Impfwirksamkeit heraus. Man muss auch dazu sagen, je weniger Krankheitsfälle zu beobachten sind, desto schlechter die Aussage. Bei der ersten Studie zu Pfizer war das Verhältnis geimpft zu ungeimpft 8 zu 162 (43.000 Probanten, Placebogruppe gleich groß wie Impfgruppe). Da kommt dann eine Impfwirksamkeit von 95% heraus. Das wichtigste ist, das so zu nehmen wie es ist und nicht zu glauben, dass damit 95% der Bevölkerung geschützt sind.
Hervorragender Artikel! Vielen lieben Dank dafür.
Sie kennen sicherlich den Spruch „Es gibt Lügen, große Lügen und Statistiken“. In dieser Zusammenhang können Sie genau so gewisse Zahlen missbrauchen wie, wie sie behaupten, die Farma Industrie macht. Sie sagen, dass das Ereignis selten auftritt. Da haben sie recht bei 800 Probanden in 6 Monaten. Die Zeit ist also zu kurz. Aber jetzt sind weltweit fast 3 miljarden „Probanden“ vollständig geimpft in fast 1 Jahr. Bei diese Gruppe ist das Ereignis (Kontakt mit Virus) in Verhältnis genau so oft aufgetreten wie bei die 800. Das ist umgerechnet das Ergebnis wie man bekommen hätte bei den 800-er Gruppe nach 1,75 miljoen Jahre. Das zum Thema große Zahlen. Man kann die Effektivität der Impfung sicherlich auch mit Statistiken klein reden aber es ist doch eindeutig, dass weltweit, dort wo geimpft worden ist die Krankenhaus Aufnahmen deutlich geringer geworden sind. Dafür brauch ich übergieß keine offizielle Zahlen vom RKI aber es reicht eine Nachfrage bei medizinisch Personal vor Ort. Oder sind das gefälschte Zahlen von den „korrupten Mediziner“? Ich bin jedenfalls froh, das Herr Wodarg nicht mein Hausarzt ist.
Hallo,
Ihr Kommentar enthält so viele Behauptungen und so wenig Fakten – was wirklich schade ist.
Sie reden von Statistik und beziehen sich hier noch nicht einmal auf die „offiziellen“ Zahlen von RKI und PEI, sondern auf Hörensagen von irgendwelchen Krankenhäusern?
Da würde uns schon eine konkrete Quelle interessieren. Ohne ins Detail gehen zu wollen, sind wir wirklich daran interessiert, was Ihre Interpretation der Zahlen aus z.B. Israel ergeben.
Naja… und wie oft ist denn bitte „wie oft“? Wir haben das Ganze hier grob abgeschätzt… wir sind auf Ihre „genaue Rechnung“ gespannt…
Wir wünschen Ihnen jedenfalls viel Glück bei Ihrem aktuellen Hausarzt – insbesondere nach dem Verabreichen der Booster-Impfung.
Aber ja – da kommen wir dann ja in die Thematik „Nebenwirkungen“, die wir hier noch gar nicht beleuchtet haben. Da können Sie ja mal recherchieren, inwiefern die deutschen Behörden es geschafft haben, die Dunkelziffer abzuschätzen…
Aber wozu sich mit solchen „Kleinigkeiten“ befassen. Wenn doch Stammtischparolen, wie die in Ihrem Beitrag, das Leben so viel einfacher machen.
Irgendwelche „Mediziner“ werden schon richtig Ahnung von der Sache haben. Und beim Rest träume ich mir irgendwas zusammen von Milliarden von Geimpften und weniger Geimpften in Krankenhäusern.
Belege? Brauchen Sie natürlich keine – das ist ja alles so offensichtlich! Genau so geht Wissenschaft – zumindest im Jahr 2021.
Viele Grüße
das Corona Blog Team
Hallo,
zuerst möchte ich ihnen bedanken, dass sie mein Beitrag veröffentlicht habe, was nicht immer der Fall ist auf „Corona-kritische“ Seiten.
Zuerst möchte ich auf die Bemerkungen eingehen.
Ich sage nicht, dass ich die RKI Zahlen nicht brauche. Die sind mir und uns allen bekannt, da die täglich bekannt gegeben werden. Mit meiner Bemerkung habe ich gemeint, dass die Zahlen bestätigt werden von Menschen, die persönlich mit Corona zu tun haben. Bei meiner Arbeit und privat, spreche ich mit viele, unterschiedlichen Menschen, die mir darüber berichten.
Das ist Pflegepersonal aus Krankenhäusern, die erzählen, dass die noch nie so viele und so schwer kranken auf IC gesehen und behandelt haben.
Das sind die Genesene, die milderen Beschwerden bis hin zum IC mir sagen: „Das möchte ich nicht nochmal erleben“
Das sind die Geimpften. In mein Umfeld sind ca. 80 % vollständig geimpft. Geschätzte 30-50 % hatten nach der Impfung meist sehr milde Beschwerden. Ein paar hatten ca. 1 Tag Grippe ähnlich Beschwerden.
Sie werden wieder sagen, dass dies Stammtischparolen sind, aber, wie schon gesagt, sind die Beobachtungen die, die offizielle Zahlen bestätigen.
Sie wollen exakte Zahlen. Der Anzahl der Weltweit geimpften findet man hier: https://ourworldindata.org/covid-vaccinations?country=DEU
Das Problem liegt glaube ich darin, dass sie den offiziellen Zahlen vom RKI usw. nicht trauen. Ich habe aber mehr vertrauen im RKI und ähnlich Instituten weltweit, als in möchte gern Wissenschaftler, DJs und Rechtsanwälten. Ich verstehe nicht, dass die meiste „Experte“ auf ihre Seiten und bei ihrer YouTube Filme ihr Bankkonto einblenden. Haben die wirtschaftlichen Interessen?
An folgendes Beispiel möchte ich meine Skepsis gegen Herr Woldarg (und andere) verdeutlichen.
Am 13. März 2020 würde auf YouTube ein Interview veröffentlicht von Herrn Woldarg mit Frau Preradovic (Schade, dass so eine kompetente Nachrichtenmoderatorin auf Abwege gekommen ist). Dies war angeblich ein Betrag der BZgA. Das Logo war auf dem Film zu sehen. Es hat mich damals schon gewundert, dass dieser Film nicht auf die offizielle Seite der BZgA zu sehen war, obwohl die mehrere Aufklärungsvideos auf ihre Seite haben. Auf YouTube ist dieses Interview noch zu sehen aber jetzt ohne Logo vom BZgA. Warum?
https://www.youtube.com/watch?v=va-3zS9q1yo&t=53s
In diesen Film wollte Herr Woldarg beweisen mit Fakten (vom EuroMoMo), dass es gar keine Pandemie gibt. Die Zahlen, worauf er seine These basierte, gaben die Übersterblichkeit an Luftweginfektionen in Europa an. Er beurteilte diese Zahlen als zuverlässig. Was er aber nicht sagte war, dass diese Zahlen, ich meine damals alle 14 Tagen veröffentlicht werden und sich basieren auf Daten der davor liegende 14 Tagen, also mit einer Verspätung von bis zur 4 Wochen. Wenn ich mir die Zahlen jetzt ansehe, lag die bis zum 10. Kalenderwoche in dem Jahr tagtägliche teilweise unter dem Durchschnitt. Aber in der 11 Woche, also der Woche wo das Video veröffentlicht würde, gab es ein „substantial increase“. Aber die Zahlen waren damals, wie gesagt noch nicht bekannt und deswegen nehme ich das, Herrn Woldarg nicht übel. Was jetzt aber wohlbekannt ist und aus der gleiche Statistik zu lesen ist, dass wir eine erhebliche Übersterblichkeit hatten zwischen Woche 11 und 20 und Woche 41-2020 und 8-2021. Diese Erhöhung lag deutlich über die Erhöhung in den Grippesaisons 2017 und 2018. Dies trotz Lockdown und andere Maßnahme. Hierbei kann noch bemerkt werde, dass es offiziell kaum Grippe im Winter 20/21 gab. Leider habe ich bis jetzt noch kein Bericht von Herrn Woldarg gelesen oder gesehen, wo er dies erklärt hat. Ich gebe zu, dass ich nicht alles von ihm lese.
https://www.euromomo.eu/graphs-and-maps/
Ich bin der Meinung, dass man über Corona sicherlich verschiedene Meinungen haben kann und darüber diskutieren sollte. Man sollte aber immer von verlässlichen Daten ausgehen. Ich basiere meine Meinung auf Daten von renommierten Instanzen, weltweit. Diese beschäftigen sich schon teils über 100 Jahr mit Infektionskrankheiten, im Gegensatz zu den vielen, selbsternannten Experten.
Auch über die Maßnahmen gegen Corona kann man diskutieren, und es gibt darin sicherlich kein Patentrezept. Aber wenn man z. B. Schweden, wo im Anfang sehr locker mit Corona umgegangen ist, mit Deutschland vergleicht, sollte man Stockholm mit Hamburg vergleichen. Die zwei Städte haben ca. die gleichen Einwohnerzahlen. In Stockholm gab es 3-mal so viel Infektionen und 2,5-mal so viel Tote. (Daten auch von our world in data.)
Ich hoffe, dass ich hiermit mein Standpunkt etwas verdeutlicht habe.
Natürlich beschreibt die relative Wirksamkeit die relative Wirksamkeit und die absolute Wirksamkeit die absolute Wirksamkeit … Was ist nun für die Impfentscheidung der wichtigere Parameter? Ich denke doch die absolute Wirksamkeit, denn sie enthält Informationen darüber, wie häufig die Krankheit überhaupt auftritt. Oder eben das Reziproke der absoluten Wirksamkeit, nämlich die Anzahl der Impfungen, die nötig sind, um eine Erkrankung zu verhindern.
Man hätte die Biontech-Studie auch beenden und feststellen können: Aha, in einem halben Jahr entwickelt nur einer von 100 Bürgern Symptome bei positivem PCR-Test, also gibt es keine Gefahr, also brauchen wir keine Impfung.
Ich habe mit Schwerpunkt auf Statistik promoviert und muss den Artikel korrigieren. Um der Eskalation vorzubeugen, ich bin sehr kritisch gegenüber sehr vielem, was politisch und medial seit 1,5 Jahren passiert, aber es ist wichtig, dass Gegenargumente inhaltlich korrekt sind.
Die Auslegung der Zahlen wird im Artikel falsch gemacht und ist richtig, wie es die BioNTech-Pfizer Studie gemacht hat.
Eine sehr verkürzte Erklärung: Ausschlaggebend ist bei Vergleichen solcher Art immer, welche Bezugsgröße die eigentlich Relevante ist für die Fragestellung. Die Fragestellung ist hier die Wirksamkeit, eine Erkrankung zu verhindern, die ohne Impfung eintreten würde (es geht nur um die Kranken, nicht um Infektionszahlen, Dunkelziffern, Asymptomatische etc). Die relevante Bezugsgröße ist daher die Zahl der Kranken, wenn niemand geimpft ist. Vorausgesetzt, dass beide Vergleichsgruppen identisch ausgewählt und behandelt wurden (mit Ausnahme der Impfung) und bei ausreichender Stichprobengröße, ist bei beiden Gruppen also eine vergleichbare Zahl von Erkrankten zu erwarten, wenn die Gruppen nicht geimpft wurden bzw. die Wirkung 0% Wirkung hat. Wenn Sie jetzt wissen wollen, wie viel % der Erkrankung verhindert werden konnte, müssen sie das prozentual zu den Erkrankten messen und nicht prozentual zu dem Gesamtsample, wovon die meisten ja überhaupt nicht erkrankt waren oder nicht einmal infiziert (diese Größen spielen keine Rolle für unsere Fragestellung). Und das sind nun einmal 100%, wenn alle ERKRANKUNGEN (=6) verhindert wurden, oder 50% wenn von 6 zu erwartenden Krankheiten nur 3 eingetroffen sind usw.
Wenn Sie einfach nur die Differenz des Prozentwerts der Erkrankten vom Gesamtsample als Absolutzahl nehmen, so wie Sie es machen, wenn Sie von 1,5% reden, dann ist das ähnlich falsch wie die Aussage, dass ein Anstieg von 60% auf 80% ein 20%iger Anstieg wäre (falsche Bezugsgrößen, Prozentpunkte als Absolutwert einfach zusammengerechnet).
Kleiner Selbstreflektionstest: Mit Ihrer Rechnung wäre es rechnerisch nicht möglich, eine 100%ige Wirkung zu erzielen, sobald es im Kontrollsample jemanden gibt, der nicht erkrankt ist. Es sollte klar sein, dass das aber nichts mit der Wirksamkeit der Impfung zu tun hat.
Wenn das immer noch nicht veranschaulicht, wieso die verwendete Bezugsgröße und Ihr Vorgehen falsch ist, stehe ich gerne für Rückmeldung per email oder Gespräch zu Verfügung. Denn dies ist kein Angriff, sondern es geht darum, sich und seine Mitsprecher mit den bestmöglichen und richtigen Argumenten auszustatten.
Hallo,
natürlich haben Sie recht – die absolute Wirksamkeit ist sicherlich auch nicht der Weisheit letzter Schluss. Allerdings ist vielleicht eine Angabe von relativer und absoluter Wirksamkeit mehr als zu empfehlen… Immerhin kommt man doch rechnerisch auf eine Wirksamkeit von 100%, wenn es nur einen Infizierten in der ungeimpften Gruppe und keinen in der geimpften Gruppe gibt.
Viele Grüße
das Corona Blog Team
Ich habe nun an verschiedenen Stellen den nachfolgenden Artikel aua 2008 gelistet bei Quarks oder bei Spiegel…keine bzw. „Wir werden recherchieren…“, aber keine Reaktion oder Antwort. Dieser Artikel vom aerzteblatt kann ja leider nicht in die Verschwörungsecke geschoben werden. Was sagen Sie dazu: https://www.aerzteblatt.de/treffer?mode=s&wo=21&s=open&typ=1&nid=34565
Oder den erwähnten Artikel hier noch https://www.pnas.org/content/early/2008/11/26/0808116105
Hatte es in einem anderen Beitrag schon einmal als Kommentar geschickt:
Auszug aus
THE LANCET Microbe
https://www.thelancet.com/journals/lanmic/article/PIIS2666-5247(21)00069-0/fulltext
„COVID-19 vaccine efficacy and effectiveness – the elephant (not) in the room
Vaccine efficacy is generally reported as a relative risk reduction (RRR). It uses the relative risk (RR)—ie, the ratio of attack rates with and without a vaccine—which is expressed as 1–RR. Ranking by reported efficacy gives relative risk reductions of 95% for the Pfizer–BioNTech, 94% for the Moderna–NIH, 90% for the Gamaleya, 67% for the J&J, and 67% for the AstraZeneca–Oxford vaccines. However, RRR should be seen against the background risk of being infected and becoming ill with COVID-19, which varies between populations and over time. Although the RRR considers only participants who could benefit from the vaccine, the absolute risk reduction (ARR), which is the difference between attack rates with and without a vaccine, considers the whole population. ARRs tend to be ignored because they give a much less impressive effect size than RRRs: 1·3% for the AstraZeneca–Oxford, 1·2% for the Moderna–NIH, 1·2% for the J&J, 0·93% for the Gamaleya, and 0·84% for the Pfizer–BioNTech vaccines.“
Von Google übersetzt:
„Die Wirksamkeit des Impfstoffs wird im Allgemeinen als relative Risikominderung (RRR) angegeben. Es verwendet das relative Risiko (RR), dh das Verhältnis der Angriffsraten mit und ohne Impfstoff, das als 1-RR ausgedrückt wird.
Die Rangfolge nach gemeldeter Wirksamkeit ergibt eine relative Risikominderung von
95% für Pfizer-BioNTech
94% für Moderna-NIH
90% für Gamaleya
67% für J & J und
67% für AstraZeneca-Oxford-Impfstoffe.
RRR sollte jedoch vor dem Hintergrund des Risikos gesehen werden, mit COVID-19 infiziert zu werden und krank zu werden, das zwischen den Populationen und im Laufe der Zeit variiert.
Obwohl die RRR nur Teilnehmer berücksichtigt, die von dem Impfstoff profitieren könnten, berücksichtigt die absolute Risikominderung (ARR), die den Unterschied zwischen den Angriffsraten mit und ohne Impfstoff darstellt, die gesamte Bevölkerung.
ARRs werden tendenziell ignoriert, da sie eine viel weniger beeindruckende Effektgröße als RRRs ergeben:
1,3% für AstraZeneca-Oxford
1,2% für Moderna-NIH
1,2% für J & J
0,93% für die Gamaleya und
0,84% für die Pfizer-BioNTech-Impfstoffe.“
Heute eine Studie über Kaffee und die Auswirkungen auf die Leber, siehe scinexx.
TEILNEHMER: 500.000, im Wort für Annalena: fünfhunderttausend
Das, was in diesem Artikel thematisiert wird, war das Erste, was ich mich gefragt habe, wie kommen die auf 95% Wirksamkeit. Als ich dann die Zahlen von BNT gesehen habe, 8 zu 162, bei ca. 21000 Probanden je Gruppe, haben mich die 95% noch mehr verwundert. Wie kommen die auf solche Zahlen? Und vor allem, das Wichtigste, wie haben sie die Leute infiziert. Das ist doch klar, daß man sich das fragt? Wenn die ganzen Geimpften eh gelockdownt waren, viell. haben die alle in nem Bunker gessesen, mit Luftfilter usw., nur 8 hatten keinen Bock etc. Das ist doch nicht Wissenschaft, das ist Lügenschaft. Und das wissen die auch alle. Ich kann nur nicht verstehen, warum so wenig Leute hinterfragen? Alle am netflixen, Playstation spielen, gehirnamputiert? Und jetzt kommt dann ja die Angst der Geimpften vor den Ungeimpften dazu. Wovor haben die Angst, bei 95-100% Wirksamkeit? Wovor?
Wirksamkeit liegt bei ca.1% -stand sogar schon in THE LANCET und Wodarg hatte das vorher auch schon genau so berechnet.Die aneren Ärzte können anscheinend nicht rechnen…
https://luegenpresse2.wordpress.com/2021/05/29/die-tatsachliche-risikoreduktion-durch-impfung-liegt-bei-ca-1-berichtet-die-bekannteste-medizinische-fachzeitschrift-the-lancet/
Ich finde den Artikel nicht ganz so gelungen.
Man sollte nicht einseitig ein Bashing des relativen Risikos betreiben. Sinnvoll ist die Betrachtung von BEIDEN Risiken bzw. Risikoveränderungen: Dem absoluten (oben 1,5% Unterschied) UND dem relativen (oben 100% Unterschied) Risiko.
Dazu sollte man sich noch die p-Werte anschauen. In diesem Fall (Impfung 0/400 ,Placebo 6/394) sollte man den Fisher Exakt Test 2seitig nutzen; der ergibt einen p-Wert von 0,0307.
In einem strengen prospektiven Test-Setting würde man dann zurecht sagen: Statistisch signifikant. Das kann man hier aber wirklich anzweifeln, vermutlich handelt es sich hier nämlich um eine „post hoc analysis“. Und dann sieht der p-Wert schon nicht mehr „so dolle“ aus.
Obige Überlegungen zur Grundinzidenz gehen da schon in die richtige Richtung. Konkret: Es steht zu befürchten, dass die 6von 394 (Placebo) eine Überschätzung der wahren Inzidenz sind. Denn hier ging es ja nur um die Untergruppe von Personen, die in Südafrika mit der sogenannten südafrikanischen Variante „infiziert“ waren. Da könnte die Inzidenz von 1,5% schon arg hoch gewesen sein.
Bei alledem … das erscheint mir als Schattenboxen. Auch die Zahlen 0/400 (Impfung) und 6/394 (Placebo) sagen rein gar nichts über die klinische Relevanz aus. Hat man dadurch vielleicht 6 Fälle von eintägigem Durchfall verhindert? Denn: Durchfall gehört in den meisten COVID-Studien seltsamerweise zu den Kriterien, wonach überhaupt ein SARS-CoV-2-Test durchgeführt werden sollte.
Und selbst dann, hätte man nur den SARS-CoV-2-positiven Durchfall verhindert, aber keineswegs Durchfälle an sich. Von Hospitalisierung und Tod ganz zu schweigen.
Wer würde das als klinisch relevant akzeptieren?
Hallo,
natürlich kann die Angabe von beiden Wirksamkeiten nicht schaden – allerdings ist eben die Angabe von ausschließlich der relativen Wirksamkeit unserer Meinung nach deutlich irreführender und irritierender als ausschließlich die absolute Wirksamkeit anzugeben oder eben beide Werte. Man „gaukelt“ den Menschen einen Sachverhalt vor, den es objektiv so nicht gibt. Wie gesagt, wenn wir einen Werbespot von BioNTech-Pfizer sehen, ist das OK – wenn wir aber Informationen beim PEI oder RKI lesen und diese auch nur diese Information weitergeben, dann ist das beunruhigend.
Zu Ihren Aussagen zu einem „Signifikanztest“ und den p-Werten. Diese Werte können natürlich (wenn man denn tiefer in die Analyse einisteigen möchte) weiterhelfen – allerdings ist es leider nur allzu häufig auch so, dass sie über ein schlechtes Studiendesign hinwegtäuschen wollen.
Man sollte nicht den (leider) typischen Fehler machen: Ich wende den nächstbesten statistischen Test auf meine Studie an und wenn mein p-Wert nur klein genug ist, dann habe ich valide Ergebnisse.
Das sieht man aber leider nur zu häufig: Schlechtes Studiendesign wird (scheinbar) ausgeglichen mit dem nächstbesten Test. Der sieht natürlich erstmal klasse aus – eine „lange, komplizierte Formel“, die man aber nichtmal richtig verstehen muss. Gibt ja mittlerweile unzählige Statistikprogramme, wo ein Klick auf den Testnamen und ein Eingeben der Rohdaten genügt, um direkt den p-Wert zu bekommen.
Wenn der Test nicht passt, wird halt der nächste genommen – gibt ja genügend.
Allerdings sollte einem immer bewusst sein, was so ein Test aussagt – in Ihrem Falle eben nur, dass die Abweichung in den beiden Gruppen wahrscheinlich nicht zufällig entstanden ist. Das wunderbare Wörtchen „signifikant“ heißt eben nicht, dass die Aussagen, die man auf Basis „nicht zufällig entstandener Daten“ trifft, richtig oder von guter Qualität sind.
Und – wenn Sie damit schon anfangen – müssen Sie dann auch auf den Fehler 2. Art eingehen und dieser hängt dann wieder vom Stichprobenumfang ab (und natürlich vom gewählten Signifikanzniveau). D.h. die Wahrscheinlichkeit einen Fehler 2. Art zu begehen, wird größer, wenn die Stichprobe klein ist.
Und was es bedeutet, wenn der Fehler 2. Art „zuschlägt“, wissen Sie ja sicherlich: Dann war nämlich im Endeffekt der ganze Signifikanztest für die Katz. Und genau diese Katze beißt sich dann hier in den eigenen Schwanz. Zu glauben, man kann ein „schlechtes Studiendesign“ (in dem Falle hier eine zu kurze Laufzeit) mit einem Signifikanztest ausgleichen ist leider ein (oft gesehener) Irrglaube und täuscht eine angebliche Qualität der Aussagen vor, die es nicht gibt.
Genau das aber kann sich jeder Mensch einfach selbst klar machen – auch eher „intuitiv“ – ohne große statistische Grundlagenkenntnisse zu besitzen. Das war das Ziel des Artikels. Wahrscheinlich werden die meisten Menschen intuitiv verstehen, dass es, um statistisch qualitativ hochwertige Aussagen zu treffen, viele Versuche braucht.
Jeder kann ja versuchen, mit 10 Würfelversuchen empirisch die Wahrscheinlichkeiten für die einzelnen Seiten des oben beschriebenen Würfels zu bestimmen. Da können Sie dann im Anschluss testen was Sie wollen, aber nicht darüber hinwegtäuschen, dass das Design der Studie einfach schlecht war und 10 Versuche halt nicht ausreichend sind, um qualitativ gute Aussagen über die realen Wahrscheinlichkeiten zu erhalten, bzw. diese exakt angeben zu können.
Viele Grüße
das Corona Blog Team
Wow, ich staune gerade nicht schlecht – nicht nur wegen des Artikels, besonders auch hier wegen der Antwort auf einen Kommentar:
Wer genau seid Ihr denn? 😉
So eine Antwort schütteln nur ganz wenige binnen 1,5 Stunden aus’m Ärmel.
Habe schon die ganze Webseite durchstöbert – ich finde keine Namen 🙂 aber so langsam wird’s „unheimlich“, ähm höchst interessant meine ich.
Guten Abend,
ja das ist tatsächlich auch gewollt und es freut uns umso mehr, dass unser Konzept, anonym zu bleiben, aufgeht.
Hin und wieder bekommen wir E-Mails in denen nach unseren Kompetenzen gefragt wird, da ohne Impressum einige Menschen, die Inhalte als nicht seriös einstufen.
Eine Nachfrage wie ihre hatten wir tatsächlich noch nie 😉
Unser Antrieb ist es, Wissen und Kompetenzen, die einfach sehr ungerecht und ungleich auf die verschiedensten Menschen verteilt sind, vielen Menschen zur Verfügung zu stellen, damit diese wie wir, mit allen Daten und Fakten, abwägen können welche Entscheidung die richtige für sie ist.
Das Team vom Corona Blog vereint sowohl rational, analytisch denkende Menschen, als auch die empathische und menschliche Komponente.
Aufgrund zu erwartender Repressalien unserer Arbeitgeber und dem finanziellen Aspekt, nicht nur diesen Blog betreiben zu können, hoffen wir auf Verständnis, dass wir weiterhin anonym bleiben werden.
Aber aufgrund von Kommentaren wie ihren immer wieder schmunzeln müssen und wissen, wieso wir das alles tun. Die Arbeit hier auf dem Blog macht einfach Spaß.
Vielen Dank
Auch für den Laien (und für alle vom Fach die sich nicht täglich mit Studien befassen) sehr gut verständlich. Danke für einen ausgezeichneten Artikel. Dr. med Andreas Köster
Nur mal als Frage in den Raum geworfen: Kann man davon ausgehen, dass beide Probandengruppen unter den selben Bedingungen gelebt haben (während der Studienzeit) und dass beide Gruppen den gleichen Risiken einer Infektion ausgesetzt waren? Haben das die Studiendesigner sichergestellt?
Diese Info würde auch uns brennend interessieren – insbesondere auch, wer die Probanden denn auswählt oder wie diese ausgewählt werden.
Wir haben bislang dazu noch nichts gefunden.
Viele Grüße
das Corona Blog Team
ich denke nicht, dass die Gruppen sich diesbzgl massgeblich unterscheiden können, und zwar wegen Randomisierung.
Gleichwohl kann man überall tricksen.
Nach Randomisierung wurden mehrere Tausend Probanden noch ausgeschlossen bzw nahmen nicht weiter teil.
Wenn man einen Auftrag angenommen hätte so eine Phase 3 Studie hinzutricksen, würde man jedenfalls zuerst mal versuchen an die Info über Gruppenzugehörigkeit eines Probanden ranzukommen.
Falls dies datensicherheitstechnisch 100pro unmöglich wäre, würde man Beobachter befragen, die unmittelbar nach Impfvorgang die Probanden noch aus Sicherheitsgründen überwachen. Evetuell zeigen sich bei einigen Probanden während dieser ersten Stunde nach Spritze bereits adverse Reaktionen, die sich mit hoher Wahrscheinlichkeit dem Impfstoff zuordnen lassen. Diese Chance hat man 2mal.
und noch besser:
die gesamte Betreuungszeit zwischen 1.Dosis und 7 Tage nach 2.Dosis ließe sich nutzen um herauszufinden wer echte Impfstoffreaktionen zeigte. Viele Probanden melden sich ja telef. wegen allen erdenklichen Symptomen. Im Gespräch lässt sich so gut erraten wer Impfstoff bekam und wer nicht. Allein schon eine größere Häufigkeit von Anrufen müsste mit Prädikat „echt geimpft“ korrelieren.
Wenn man so erstmal eine Liste angelegt hat, gilt es PCR-Tests für Impfgruppe zu minimieren, während Tests für Kontrollgruppe maximiert werden.
Daß Anzahl und Verteilung der PCR-Tests nicht in Studienprotokoll erfasst sind, spricht Bände.
Ferner hätte der zusätzliche Endpunkt „PCR-TEST pos“ (unabhängig von Symptomen) unbedingt zu einem seriösen Studiendesign dazu gehören MÜSSEN !
Dies allein schon, weil die befürchtete asymptomat. Übertragung ja das eigentlich besondere und tückische an Cov2 hatte sein sollen.
Man brauchte dazu nur wöchentlich 1x zu testen und hätte nebenbei wegen weit mehr Treffern seine Studie auch statistisch weitaus aussagestärker und belastbarer gemacht.
Weil EMA bzw PEI /RKI diese Studien ja bekanntlich zwecks Zeitgewinn ständig begleiteten und auch zuvorderst das Studiendesign genehmigen hatten müssen, fällt es auf die beteiligten Institute zurück, wenn unterblieb, was nicht hätte unterbleiben dürfen.
und noch ne kriminelle Idee:
Die derart vermuteten Nicht-Geimpften könnte man bei jeder Gelegenheit persönlichen Kontakts, also bei Einbestellung zwecks Symptomkontrolle oder zwecks PCR Testung versuchen gezielt zu infizieren!
Dank Aerosolen unbemerkbar möglich.
Virionen aus dem Sack – in den Warteraum hinein, Maske bringt gar nichts bei mehrminütigem Aufenthalt.
Woher die Virionen zu beschaffen wären, verrat ich hier mal nicht. Habe aber praktikable wie preisgünstige Idee dazu.
Gezielte sonstige Verhaltensbeeinflußung einzelner Probanden ist natürlich auch denkbar… mit Ziel diese zu infizieren. Tage später ruft man sie routinemässig an um Symptome abzufragen, die man dann suggeriert und infolge zum Test bittet.
Es brauchten ja nur ca 100 Probanden aus Kontrollgruppe auf die eine oder andere Weise derart positiv testbar gemacht zu werden.
Wichtigstes Instrument :
vermutete PROBANDEN aus KONTROLLGRUPPE OFT TESTEN,
andere selten bis nie testen.
und nun noch der hoffentlich krönende Abschluß meiner kriminellen Gedankenspiele:
Wäre es nicht ideal ein Adjuvanz oder sonstwas beizugeben, daß eine harmlose, aber eindeutige Reaktion auslöst.
Das könnte dem verabreichten Impfstoff zugegeben werden,
oder aber auch dem Placebo!
oder gar für jede Gruppe ein eigenes *g
tja, für Dutzende an Milliarden Dollar strengt man sein Kreativköpfchen schon mal an
Das hab ich schon vor 1 Jahr gesagt und in der öffentlichen Debatte fand diese Überlegung bis heute nie statt.
Die Prävalenz des Virus in der Bevölkerung war schon immer so gering, dass zufällige Ereignisse, wie ein Superspreader, die Ergebnisse in der Placebogruppe ganz leicht krass verfälschen konnten. Wie kann man auf dieser Basis überhaupt Impfungen zulassen? Ein unfassbarer Skandal.
Zusätzliche traue ich den Impfstoffentwicklern zu, über die Studienteilnehmerauswahl/selektion die Studien zu verfälschen. Die sagen uns nicht mal wo die Studien durchgeführt wurden und in welchem Zeitraum!
Und generell sind die Infiziertenzahlen in den Studien zu gering um von statistischer Relevanz sprechen zu können. Und auf dieser Basis werden Millionen geimpft! Eine der grössten Irrsinnsaktionen der Menschheitsgeschichte.
Häufig werden Medikamentenstudien in Indien, Brasilien, USA durchgeführt, unter der ärmeren Bevölkerung, in USA auch gern unter Farbigen, da zur Belohnung gerne Geschenke abgegeben werden. Wie beeinflussen Belohnungen für die Teilnahme das Studienergebnis? Gibt es darüber Untersuchungen?
Fundamentale Falschannahme: Es gibt einen solchen Virus.
Es liegt kein Erreger Nachweis vor.
Ohne Erregernachweis ist folgendes unmöglich:
Symptom-zuordnung
Krankheitsbestimmung
Testentwicklung
Impfstoffentwicklung
Und wenn sich eben herausstellt dass die gesamte Virologie unwissenschaftlich ist, und bis heute reine Vermutungskunst darstellt, dann ist es an der Zeit diesen Humbug hier und jetzt zu beenden.
Ich stimme Ihnen zu 100% zu und verweise an dieser Stelle gerne einmal auf ein Preisgeld in Höhe von 1,5 Millionen Euro für den wissenschaftlichen Nachweis der Existenz des SARS-CoV-2 bezeichneten Virus anhand von Vorgaben, die sich die Wissenschaft selbst für den Nachweis von Krankheitserregern auferlegt hat.
Nachzulesen auf https://www.samueleckert.net/isolate-truth-fund/
Komplett falsch. Natürlich gibt es einen Erregernachweis und die Formulierungen der Wette sind ganz bewusst so gewählt worden, dass sie nicht erfüllbar sind. Es geht bei der Wette eben nicht um einen Erregernachweis. Diese ganze Aktion ist leider mehr als unseriös und schadet daher der Glaubwürdigkeit des Widerstandes.
Der Artikel ist dagegen hervorragend. Ich weise darauf schon seit der ersten Veröffentlichung der Impfstudien hin. Leider wollen viele diese Wahrheit nicht wahrhaben, sonst müssten sie ja zugestehen, dass wir belogen werden. Da kann selbst ein Institut wie das RWI-ESSEN die Angabe einer 90%igen Wirksamkeit zur Unstatistik des Monats küren, es nützt nichts, man will an die Lüge glauben.
Sehe ich auch so. Die von Samuel Eckert ins Leben gerufene Wette schadet einer sachlichen Auseinandersetzung und ärgert mich schon lang.
Dass die Placebos ebenfalls eine Art „Impfstoffe“ darstellen, die ebenfalls Nebenwirkungen zeigen ist bekannt. Allerdings ist fraglich, ob diese in vergleichbarer Quantität erzeugt werden. Ansonsten vermute ich, dass Menschen, mit Symptomen wie Kopfschmerzen, Fieber etc. ( also häufige Nebenwirkungen nach mRNA Impfungen) sich in den Wochen danach ggf weniger aktiv am sozialen Leben beteiligen und damit wiederum die Ansteckungswahrscheinlichkeit noch geringer ausfällt.
Bhakdi und Wodarg haben gesagt das es Isolate gibt.Nur vom „Ursprungsvirus“aus Wuhan gibt es keins und das kann man auch nicht mehr finden weil sich das Virus ja eben verändert.
Allerdings ist es komisch das die Chinesen angeblich auch keins haben…
Dass hab sogar ich verstanden
Und auch bedenken: Es gibt hier keine Placebo-Gruppe, denn die „Impfung“ verursacht fast immer starke Impfreaktionen. Es ist den Probanden also bekannt, ob sie geimpft sind oder nicht… und wer geimpft wurde fühlt sich vielleicht sicher und geht nicht zum Arzt mit „leichten Symptomen“.
Sind das echte Placebos ohne irgendeine Wirkung? Lanka meinte mal in einem Video, dass in den Placebo-Imfpungen zwar der tatsächliche Wirkstoff der Impfung fehle, dafür aber die anderen Inhaltsstoffe, Adjuvantien etc. enthalten sind. Auch die haben Nebenwirkungen und es würde eigentlich auch Sinn machen um Reaktionen dem Wirkstoff zuordnen zu können.
Ich denke da ist etwas dran, denn in den Infos zu der Pfizer Studie an den Kindern wurden die gleichen Nebenwirkungen für beide Gruppen aufgeführt. Bei der Placebo Gruppe waren die Zahlen jedoch niedriger.
Hi, ja das ist so, wie Sie schreiben. Dr. Schmidt-Krüger hat das Thema auch beleuchtet und auch schon lange vorher, haben die Firmen hier richtig beschi**en. In der Studie war es also Adjuvantien-Placebo und in der Veröffentlichung Placebo.
Was z. Bsp. BNT genau als Placebo gespritzt hat, bleibt wohl deren Geheimnis. Im Normalfall jedoch alle Zutaten, ohne den eigentlichen Wirkstoff, in dem Fall die mRNA, ansonsten wohl die LipidNanoPartikel.
https://www.youtube.com/watch?v=y2mrhbIIrLw
Dieses Video ist von 2014, spricht aber Bände, heute würde es sicher sofort gelöscht werden.